Como uma rede neural funciona? Entenda o que está por trás de muitas inteligências artificiais
Muitas ferramentas de inteligências artificiais que vemos hoje tem por trás algo chamado de redes neurais. Mas o que é uma rede neural e como ela funciona?

Atualmente, vemos o avanço da presença de inteligência artificial nas nossas vidas. O ChatGPT e o GPT escancarou o potencial que a inteligência artificial tem de fazer tarefas desde responder perguntas sobre algo até resolver problemas simples de Matemática. Também vivemos em contato com sistemas de recomendação nas redes sociais diariamente.
A primeira vista, a capacidade da inteligência artificial parece mágica. Alguns até criam teorias da conspiração que esses modelos possuem consciência. Porém, a realidade é um pouco mais simples do que isso. Por trás desses modelos há uma ferramenta essencial que faz esses modelos funcionar: a Matemática.
Mais especificamente, muitos desses modelos estão baseados em redes neurais. O próprio ChatGPT possui uma arquitetura inspirada nas redes neurais. Mas o que são elas? Como elas funcionam? E por que elas funcionam tão bem ao ponto de parecer um passe de mágica?
Uma breve história das redes neurais
Na década de 40, dois cientistas propuseram um modelo matemático de como um neurônio biológico funcionava. O artigo A Logical Calculus of the Ideas Immanent in Nervous Activity é considerado como o primeiro marco na história das redes neurais. Na década seguinte, o psicólogo Frank Rosenblatt construiu o primeiro neurônio artificial com base nesse trabalho.
Com o avanço da tecnologia e dos hardwares, foi na década de 80 que as redes neurais tiveram um avanço considerável. Agora, os neurônios artificiais eram ligados uns aos outros formando uma rede que levou nome de rede neural. Outras técnicas para o aprendizado dessas redes também foram introduzidas. E até hoje, técnicas para redes neurais é um campo rico dentro da inteligência artificial.
O que é uma rede neural?
Uma rede neural é composta por neurônios artificiais, também chamados de nós, que estão interligados para processar informações. A forma como a rede neural processa informação é inspirada na forma que a rede neural biológica passa informações entre os neurônios. Um neurônio artificial se assemelha muito a um esquema de um neurônio biológico.

O neurônio artificial possui estruturas inspiradas na estrutura de um neurônio biológico:
- Entradas: é onde o neurônio recebe as informações da camada de entrada ou de outros neurônios. Cada entrada tem um peso associado que representa a contribuição dessa entrada para o neurônio. Inspirado nos dendritos dos neurônios biológicos.
- Núcleo: o núcleo pode ser considerado como a soma ponderada das entradas. A soma ponderada é a multiplicação dos pesos pelas entradas e a soma de tudo. A analogia seria com o núcleo dos neurônios biológicos.
- Saída: Após a soma ponderada, é aplicada uma função de ativação. Como o nome diz, ela define como e se aquele neurônio será ativado para passar a informação para frente. O resultado será passado para outros neurônios ou para a camada de saída. Isso é muito semelhante à função de um axônio.
Há outras características que podem estar presentes no neurônio artificial como a presença de um peso extra chamado bias. Além disso, outros tipos de neurônios já foram introduzidos que possuem mais estruturas ou estruturas diferentes. Porém, o neurônio tradicional é como descrito acima.
Neurônios conectados
Inspirado na complexidade do sistema neural humano, os neurônios são interligados uns aos outros para formar a rede neural com maior complexidade. Modelos simples pode conter de algumas unidades até centenas de neurônios. Já outros podem possui até milhões ou bilhões de neurônios.
A rede neural é divididade em camadas: camadas de entrada, camadas ocultas e camadas de saída. O famoso nome de rede neural profunda vem justamente pela “profundidade” dessas camadas, ou seja, a quantidade de camadas presentes. É também daí que vem o nome aprendizado profundo ou, em inglês, deep learning.
A anatomia de uma rede neural
A primeira camada é chamada de camada de entrada. Essa camada será a responsável por receber os dados ou informações do ambiente externo. Quando você alimenta dados para uma rede neural, é a camada de entrada que receberá e processará esses dados. A camada de entrada é formada por neurônios, a diferença é que recebem os dados que não passaram por outros neurônios.

As camadas ocultas são compostas por mais neurônios e, em geral, elas que são responsáveis pelo processamento e parte do aprendizado. Elas irão receber informações uma das outras e passar para frente depois de ter sido processado em seus núcleos.
Por fim, a camada de saída irá receber os resultados das camadas ocultas e produzir um resultado final. O resultado final pode ser uma previsão, uma classificação ou outro tipo de saída dependendo do problema.
Mas como elas aprendem?
O segredo todo está nos pesos presentes. Os pesos serão ajustados para que a rede neural consiga aprender a mapear as entradas até as saídas desejadas. Podemos imaginar a rede neural como uma função matemática que possui entradas (x) e a função possui pesos (w). O que queremos é que a função retorne um resultado esperado.

Há diferentes formas dos pesos serem ajustados mas a mais comum é através do aprendizado supervisionado. O aprendizado supervisionado informa à rede qual é o resultado esperado e após calcular o erro entre o resultado esperado e o resultado que a rede chegou, ela informará aos pesos onde se ajustar.
O ajuste dos pesos é considerado como o aprendizado em si. O objetivo é encontrar os pesos que consigam ajustar a rede neural de forma que ela consiga receber os dados de entrada e retornar o resultado esperado.
Matematiquês das redes neurais
Uma forma simplificada de pensar em redes neurais é que ela é uma função: ŷ = F(X, W) onde ŷ é a resposta final que ela chega, X são os dados de entradas e W são os pesos. Ao final da rede neural em um aprendizado supervisionado, o resultado ŷ será comparado com o resultado esperado y através de uma função de erro, L.
A função de erro será responsável por informar aos pesos W quanto eles terão que ser ajustados. Isso acontece através de uma ferramenta matemática chamada gradiente. O negativo do gradiente da função informa para onde a função de erro diminui, ou seja, onde está o erro mais baixo.
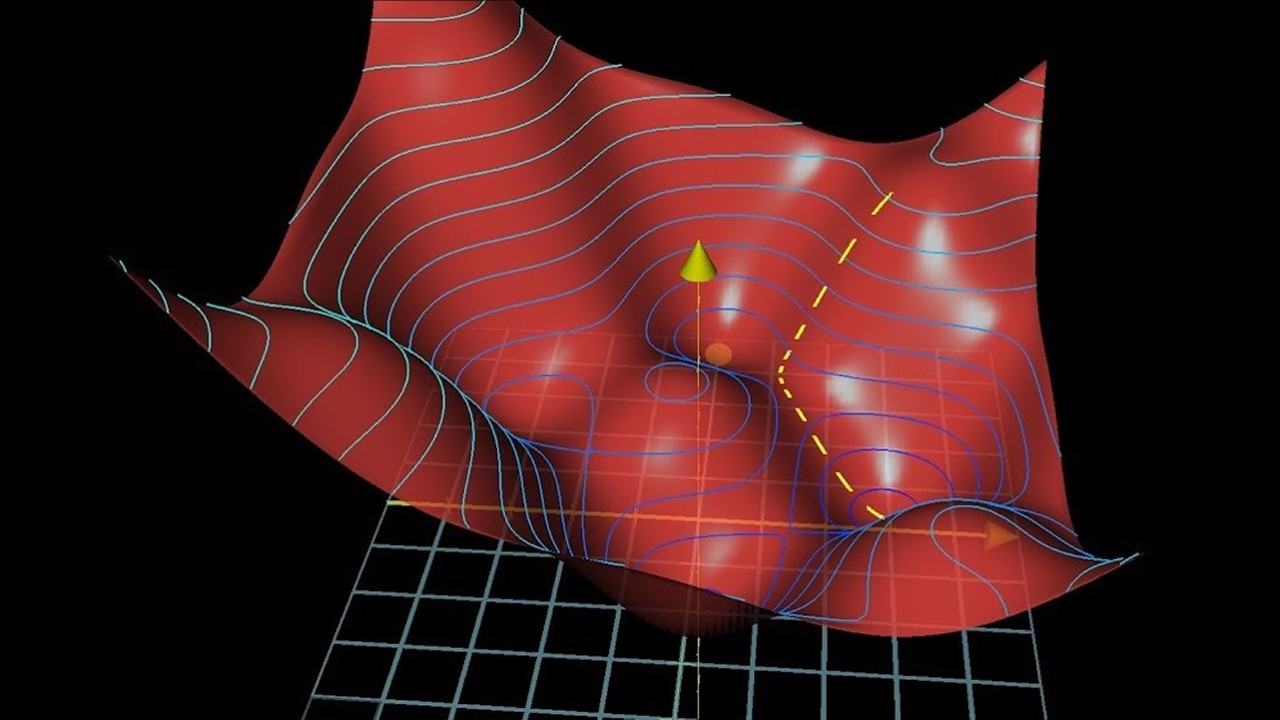
O processo de aprendizado é feito diversas vezes com diversos dados até que os pesos atinjam onde a função está com o erro mais baixo ou próxima do erro mais baixo. Ainda há um campo de pesquisa em aberto estudando se existe um mínimo global para todas as funções.
Um exemplo prático
Imagina que você queira uma máquina usando rede neural que consiga diferenciar cachorro e gato. Primeiro, você consegue milhares de fotos de cachorros e gatos com a devida classificação (cachorro nas fotos de cachorro e gatos nas fotos de gatos).
Na camada de saída, a rede retornará uma classificação referente à gato ou à cachorro. Nisso, uma função de erro irá quantificar o quão errada ou certa a rede estava e através dela alterar os pesos presentes na rede. Milhares de fotos irão passar por esse processo até chegar em um resultado ideal.
Por que usar rede neural?
As redes neurais tem tido casos de sucesso desde que foram introduzidas. A cada ano novas técnicas e métodos para otimizar o aprendizado são introduzidos, além da tecnologia com os hardwares melhorar e ser possível criar redes cada vez mais complexas.
Atualmente, boa parte das aplicações de inteligência artificial que vemos são usando redes neurais ou algo inspirado em redes neurais, como é o caso do ChatGPT. O ChatGPT utiliza transformers que é uma espécie de neurônio modificado para aprender sequências, como frases e textos.